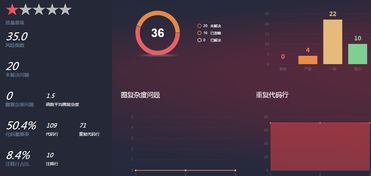
本次測(cè)評(píng)聚焦于華為軟件開發(fā)云的代碼檢查功能,旨在評(píng)估其在軟件開發(fā)流程中的實(shí)際應(yīng)用價(jià)值。代碼檢查作為軟件開發(fā)的重要環(huán)節(jié),直接影響代碼質(zhì)量、團(tuán)隊(duì)協(xié)作效率以及項(xiàng)目的長(zhǎng)期可維護(hù)性。
一、代碼檢查功能概述
華為軟件開發(fā)云提供了一套集成化的代碼檢查工具,支持Java、Python、C++等多種主流編程語(yǔ)言。通過(guò)自動(dòng)化的代碼掃描,該工具能夠快速識(shí)別代碼中的潛在問(wèn)題,包括語(yǔ)法錯(cuò)誤、代碼風(fēng)格不一致、安全漏洞以及性能瓶頸等。用戶可通過(guò)配置檢查規(guī)則,自定義檢查策略,確保代碼符合團(tuán)隊(duì)或行業(yè)標(biāo)準(zhǔn)。
二、測(cè)評(píng)內(nèi)容與方法
本次測(cè)評(píng)從以下幾個(gè)維度展開:
- 檢查準(zhǔn)確性:通過(guò)提交包含典型錯(cuò)誤的代碼樣本,驗(yàn)證工具是否能準(zhǔn)確識(shí)別問(wèn)題并提供詳細(xì)報(bào)告。
- 易用性:評(píng)估用戶界面友好程度、配置流程的簡(jiǎn)便性以及結(jié)果的可讀性。
- 集成性:測(cè)試與其他開發(fā)工具(如版本控制、CI/CD流水線)的協(xié)同能力。
- 性能表現(xiàn):檢查在大規(guī)模代碼庫(kù)中的掃描速度和資源占用情況。
測(cè)評(píng)方法包括實(shí)際操作華為軟件開發(fā)云平臺(tái)、分析輸出報(bào)告,并與行業(yè)標(biāo)準(zhǔn)工具(如SonarQube)進(jìn)行對(duì)比。
三、測(cè)評(píng)結(jié)果分析
- 準(zhǔn)確性方面:華為軟件開發(fā)云的代碼檢查工具在識(shí)別常見代碼缺陷(如空指針異常、資源未釋放)方面表現(xiàn)優(yōu)異,誤報(bào)率較低。但對(duì)于一些復(fù)雜的邏輯錯(cuò)誤,仍需結(jié)合人工審查。
- 易用性:平臺(tái)提供了清晰的可視化報(bào)告,問(wèn)題分類明確,并附有修復(fù)建議。新手用戶可通過(guò)默認(rèn)配置快速上手,高級(jí)用戶則能靈活定制規(guī)則。
- 集成性:該工具與Git倉(cāng)庫(kù)、Jenkins等常見DevOps工具無(wú)縫集成,支持在代碼提交或構(gòu)建階段自動(dòng)觸發(fā)檢查,有效嵌入開發(fā)流程。
- 性能:在測(cè)試的萬(wàn)行代碼庫(kù)中,掃描平均耗時(shí)在5分鐘內(nèi),資源消耗可控,適合持續(xù)集成環(huán)境。
四、優(yōu)勢(shì)與改進(jìn)建議
華為軟件開發(fā)云代碼檢查功能的優(yōu)勢(shì)在于其云原生架構(gòu)、多語(yǔ)言支持以及與企業(yè)現(xiàn)有工具的深度整合。建議在以下方面進(jìn)行優(yōu)化:
- 增加對(duì)更多小眾語(yǔ)言和框架的支持;
- 提供更豐富的自定義規(guī)則模板;
- 加強(qiáng)安全漏洞檢測(cè)的深度,例如引入AI輔助分析。
五、總結(jié)
總體而言,華為軟件開發(fā)云的代碼檢查功能在提升代碼質(zhì)量、規(guī)范開發(fā)流程方面發(fā)揮了重要作用。其準(zhǔn)確性、易用性和集成性均達(dá)到行業(yè)領(lǐng)先水平,適用于各類軟件開發(fā)團(tuán)隊(duì),尤其是追求高效協(xié)作和高質(zhì)量交付的企業(yè)。結(jié)合華為云的整體生態(tài),該工具為現(xiàn)代軟件開發(fā)提供了可靠保障。









